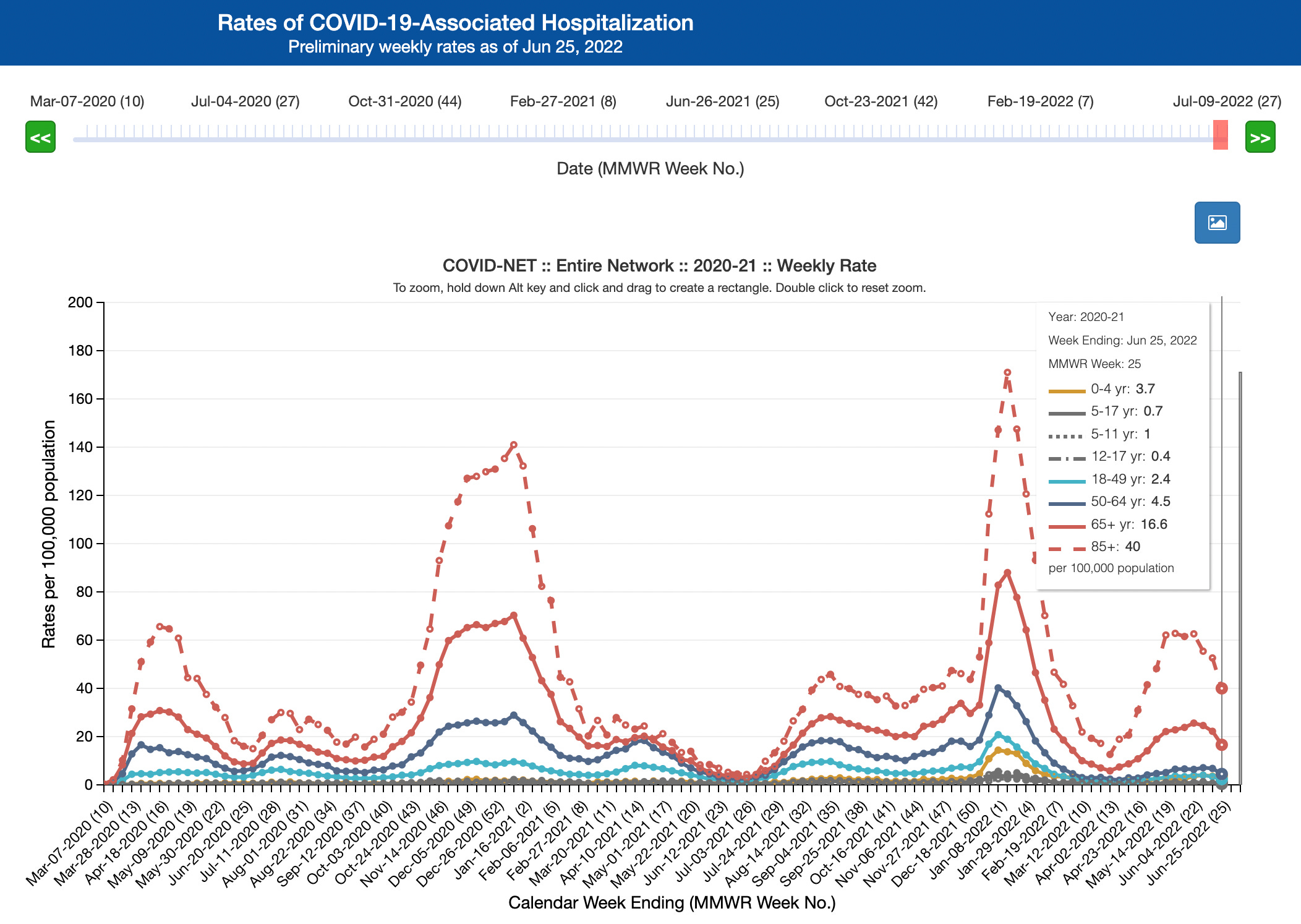
The above map is an illustration to understand what we are discussing in the article below. The background colors represent Chomonicx. A clustering system at the Chome level. The points represent single buildings. This is what we call Point System, a clustering system at the building level from which we can infer single households. Our breakthrough is to obtain this last level of precision from the address with limited input from external data and no need to refer to an address database which in Japan tends to be expensive.
This post is a follow-up to an earlier post concerning clustering in Japan. Clustering with knowledge instead of data (Marketing) Part-1 explaining how over time knowledge replaced data at the base of our clustering system.
Initially, moving from Chome (block) level clustering to Point (household) level clustering we encountered several challenges.
The first one was the de-identification of data in order to respect privacy. But this is a well known problem which has been solved by Internet companies with one way hash solutions by combining several data lines, address and phone number for example, so that you end up with a unique identification number which can be matched but cannot for calculated back to a specific individual or original data.
The second challenge was that we were using proxy data (addresses) in order to build an index on data, households, about which we had no information. The solution was to identify “income” as the most important data about households since this is the main link and constraint to the propensity to buy, and income could easily be calculated from the size, location and value of each dwelling.
The third challenge was to corroborate this insight by extensive verification and validation which was complex and time consuming although we were in a unique position to do it since our partner at that time, Zenrin, had built and just digitized their full database of all the buildings in Japan.
Lastly, we had to compile all this information into a coherent whole but that too was well understood thanks to the construction of our earlier segmentation systems, the different versions of Chomonicx at a higher level of coverage.
Point System
Marketing up until recently was defined by a few principles which have now been rendered void by the implementation of Internet Marketing.
The first principle was the 80/20 rule so that 80% of
your income was generated by 20% of your customers. The Internet replaced this
basic marketing tenet with the “winner takes all” 99/1 where 99% of
your success is generated by 1% or less of your insight. This is specifically
the case for clustering as the very few top clusters generate most of your income.
A direct consequence of this is that you do not need to be right most of the time.
You just need to be perfectly right a few times. This phenomenon is well known
with Twitter for example as most of your Tweets will have a few or a few
hundred retweets until an influencer retweet your post in which case it will
suddenly become viral and be copied into the millions. Likewise, on the
Internet, a successful cluster will be used out of proportion compared to less
well targeted ones, even if the difference is marginal.
The second principle of marketing was the 50% rule of impact. “Half of my advertising works but I don't know which half!” This was then, now we know. The instant feedback from on-line advertising means that over time the impact and therefore knowledge accumulated becomes extremely effective and eventually statistically overwhelming. These knowledge building loops are of course directly applicable to segmentation and have yielded astounding improvements in segment precision.
Consequently, some of our clusters, Young urban high-earning singles in small expensive central flats for example are almost perfect and indeed include such people to the exclusion of anybody else. This is precision targeting at its best.
Addresses
But how far could we go on this road of “less data, more knowledge” without losing the insight giving value to our system? As in a Turner or Van Gogh painting, can you still get the gist with almost no data, but talent in their case, knowledge in ours? The answer to this question was positive. For technical and specific geographic reasons, it happens that the addresses in Japan contain all the information you will ever need, to build a clustering system.
This has profound implications as it means that with the right knowledge and input, almost anyone can build an effective segmentation system. To understand why, let’s see below how the address system works in Japan.
In Western countries the address systems are defined by streets and their numbering usually in ascending order away from a river with pair numbers on one side and odd numbers on the other side. Streets can be dense and short in old city centers or kilometers/miles long, in the US.
In contrast, the Japanese system (Originally Chinese) considers “streets” as a gap between blocks of houses and consequently never bothered to give them names. The number for each house is given in chronological order based on the date of construction on a block which is called a Banchi. The Banchi are grouped in Chome which are themselves grouped in areas which are grouped in villages or cities in a perfect hierarchical order.
This has a number of positive consequences for segmentation. The Banchi, Chome and city areas are more or less homogeneous in size and sometimes, but not always, composition and cover Japan with geographic blocks which are extremely easy to manipulate both statistically and on Maps (GIS).
A typical address will therefore look like the following: (When written in Japanese. If written in English we invert the naming and numbering system which completely destroys the logic.)
Chiba-ken, Narita-shi, Tamatsukuri. 5-12-3
Chiba is the prefecture (Ken), Narita is the city (Shi), Tamatsukuri is the area, 5 is the Chome, 12 is the Banchi and 3 the number of the house.
If the information stopped there, we would have a convenient hierarchical address system but nothing very useful for clustering.
Fortunately and surprisingly, the Japanese do not stop there as usually they also include the name of the building if it is a large building as well as the floor number. So the address above which as such would indicated a single detached house now becomes:
Chiba-ken, Narita-shi, Tamatsukuri. 5-12-3-12F Green mansion
or Chiba-ken, Narita-shi, Tamatsukuri. 5-12-3-3F Momiji-so
The number of floors is of course important as it tells us the size of the building. As for the name, it is essential as it gives an indication of the type of building. In the examples above, Mansion indicates a family size flat whereas "so" indicates a single room “apato”. A much cheaper type of construction.
Likewise, addresses in countryside areas are defined by only two numbers instead of three which immediately indicates a rural area. So the address above would become:
Chiba-ken, Hatake-Machi. 1435-56
Or Chiba-ken, Hatake-Machi. 1435-56-3F
In the first case, you have a house in the countryside, in the second a building.
But it goes far beyond that: If you have a company or a store included, you can easily match the address to a public registry of all the companies in Japan. If it is a town or city flat, the name “Danchi” will replace “Mansion”. And finally, the land price for ALL the cities and villages at the Banchi level are public in Japan (and published in the newspapers once a year.)
So in the end, just based on the address system, we will know for every building in Japan, if it is a flat, a mansion or a government provided apartment, the number of floors as well as the land price.
All this information is enough to build a very accurate segmentation system as a precise land price will tell you the level of urbanization and the rest of the address indicate the type of building. This information is sufficient to build an accurate and effective segmentation system based on an inferred income level.
The most important characteristic is that the information does not need to be matched to an address database to get access to the data as for any other segmentation system, but just to extract and recognize the information directly provided in an address database, to automatically segment and organize it.
The exact algorithm contains of course more information and details at every level of the address system but is not significantly more complex than described above. What is not included in our description is little more than specific details to refine and define further the addresses as other types of details can be included in an address and therefore taken into consideration to improve the segmentation.
This is how, over 15 years, we have succeeded in replacing data with knowledge, substituting a simple but astute groupings algorithm to matching addresses with an existing database, which in itself represents a huge progress since a few hundred lines of algorithm are enough to completely replace a one to one matching to an existing, but usually expensive database.